






hivt的进化版(不先看hivt也能直接读这篇),性能和效率上大幅提升。
文章也很容易阅读。
【轨迹预测系列】【笔记】HiVT: Hierarchical Vector Transformer for Multi-Agent Motion Prediction - 知乎 (zhihu.com)
原文链接:
https://openaccess.thecvf.com/content/CVPR2025/papers/Zhou_Query-Centric_Trajectory_Prediction_CVPR_2025_paper.pdf
Abstract
Agent作为中心进行预测的模型存在一个问题,当窗口移动时需要多次重复normalize到agent中心,再进行重复encoding的过程,对于onboard使用是不划算的。因此对于场景的encoding我们采用了query-centric的框架,可重复使用已经计算过的结果,不依赖于全局的时间坐标系。同时,因为对于不同agent共享了场景特征,使得agent的轨迹decoding过程可更加并行化处理。
对于场景进行了复杂的编码,目前的解码方法对于mode的信息抓取还是比较困难,特别是对于长时间的预测。为了解决这个问题,我们首先使用anchor-free的query生成轨迹proposal(走一步看一步的提取特征方法),这样model能够更好利用不同时间刻位的场景特征。然后是调整模块,利用上一步得到的proposal来进行轨迹的调优(动态的anchor-based)。通过这些高质量的anchor,我们的query-based decoder可以更好地处理mode的特征。
打榜成功。这个设计也实现了场景特征encoding和并行多agent的decoding的pipeline。
Introduction
目前的轨迹预测paper有这么几个问题:
- 对于多种异构的场景信息额度处理效率低下。无人驾驶任务里,数据以一帧一帧的流给到model,包含矢量化的高精地图和周围agent的历史轨迹。最近的factorized attention方法(时空分开分别进行attentin)将这些信息的处理提升到新高度。但这需要对于每个场景元素做attention,如果场景非常复杂,cost还是很大的。
- 随着预测的时间增长,预测的不确定性也在爆炸式增长。比如在路口的车可能直行或转弯。为了避免错过潜在的可能性,模型需要获取多mode的分布,而不是仅仅只预测出现频率最高的mode。但是gt只有一个,没法对多个可能性进行比较好的学习。有些paper提出了多个手捏的anchor来监督的做法,这个效果就完全取决于anchor的质量高低了。当anchor无法准确cover gt时,这个做法就很糟糕了。也有别的做法直接预测多mode,忽视了mode塌缩和训练不稳定的问题。
为了解决上述问题,我们提出了QCNet。
首先,我们想要在利用好强大的factorized attention的同时,提高onboard的inference速度。过去的agent-centric encoding办法显然不行。当下一帧数据到来,窗口就会移动,但还是和上一帧有很大部分重叠的,所以我们有机会重复使用这些feature。但是agent-centric办法需要转到agent坐标系,导致其必须要重新encode场景。为了解决这个问题,我们使用了query-centric的办法:场景元素在它们自己的时空坐标系内进行特征提取,和全局坐标系无关(ego在哪无关了)。(高精地图可以用因为地图元素有长久的id,非高精地图应该就不好用了,地图元素的得在前后帧tracking住 )
)
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜
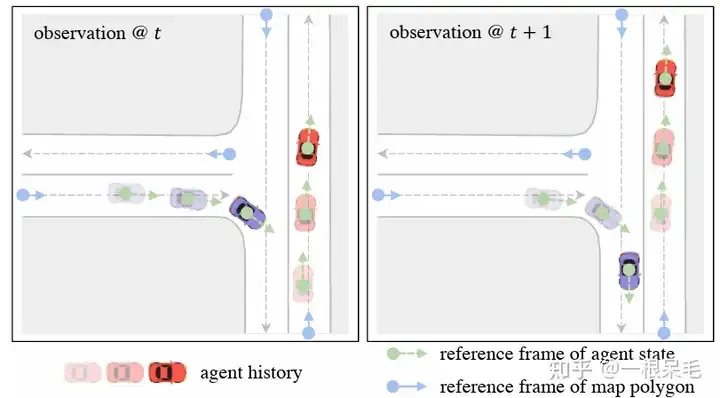
这使得我们可以把之前处理好的encoding结果进行重复使用,对于agent来说直接用这些cache的feature,这样就能节省latency了。
其次,为了更好地用这些场景encode结果进行多mode长时间预测,我们使用了anchor-free的query来一步步(在上一个位置的地方)提取场景的feature,这样每一次的decode都是非常短的一步。这个做法可以使得对于场景的特征提取重心放在agent未来在的某一个位置,而不是为了考虑未来多个时刻的位置,去提取远处的feature。这样得到的高质量anchor会在下一个refine的module进行精细调整。这样结合了anchor-free和anchor-based的做法充分利用了两个办法的优点,实现多mode长时间的预测。
这个做法是第一个探索了轨迹预测的连续性来实现高速inference的办法。同时decoder部分也兼顾了多mode和长时间预测的任务。
Approach
Input and Output

同时prediction模块还可以从高精地图获得M个polygon,每一个polygon都有多个点以及语义信息(crosswalk,lane等类型)。
预测模块使用T个时刻的上述的agent state和地图信息,要给出K个总共T'长度预测轨迹,同时还有其概率分布。
Query-Centric Scene Context Encoding
第一步自然是场景的encode。目前流行的factorized attention(时间和空间维度分别做attention)是这么做的,具体来说一共有三步:
- 时间维度attention,时间复杂度O(A),每个agent自己的时间维度矩阵乘法
- agent和map的cross attention,时间复杂度O(ATM),在每个时刻,agent和地图元素的矩阵乘法
- agent和agent间的attention,时间复杂度O(T), 在每个时刻,agent和agent矩阵乘法
这个做法和之前的先在时间维度压缩feature到当前时刻,再agent和agent,agent和地图间交互的做法比起来,是对于过去每个时刻去做交互,因此可以获取更多信息,比如agent和map间在每个时刻的交互演变。
但是缺点是三次方的复杂度随着场景变复杂,元素变多,会变得很大。我们的目标就是既用好这个factorized attention,同时不让时间复杂度这么容易爆炸。
一个很容易想到的办法是利用上一帧的结果,因为在时间维度上其实有T-1帧是完全重复的。但因为我们需要把这些feature旋转平移到agent当前帧的的位置和朝向,因此没法就这么使用上一帧运算得到的结果。
为了解决坐标系的问题,采用了query-centric办法,来学习场景元素的特征,而不依赖它们的全局坐标。这个做法对每个场景元素建立了局部的时空坐标系,在这个坐标系内提取特征,即使ego到别处,这个局部提取出来的特征也是不变的。这个局部时空坐标系自然也有一个原点位置和方向,这位置信息作为key,提取出来的特征作为value,便于之后的attention操作。整个做法分为下面几步:
Local Spacetime Coordinate System
对于agent i在t时刻的feature来说,选择这个时刻的位置和朝向作为参考系。对于map元素来说,则采用这个元素的起始点作为参考系。这样的参考系选择方法可以在ego移动后提取的feature保持不变。
Scene Element Embedding
对于每个元素内的别的向量特征,都在上述参考系里获取极坐标表示表达。然后将它们转成傅里叶特征来获取高频信号。concat上语义特征后再MLP获取特征。对于map元素,为了保证内部点的顺序不相关性,先做attention后pooling的操作。最后获得agent特征为[A, T, D], map特征为[M, D]. D是特征维度,保持一致才可以方便attention的矩阵相乘。这样提取出来的特征可以使得ego处于任何地方都能使用。
傅里叶embedding: 制造正态分布的embedding,对应各种频率的权重,乘输入和2Π, 最后取cos和sin作为feature。直观理解的话应该是把输入当作一个信号,把信号解码成多个基本信号(多个频率的信号)。这样可以更好的抓取高频信号,高频信号对于结果的精细程度很重要,一般的做法容易丢精细的高频信号。值得注意的是对于noisy数据不建议使用,因为会误抓错误的高频信号。(感觉有点像overfit,不能太general但又不能精准过头)
Relative Spatial-Temporal Positional Embedding

Self-Attention for Map Encoding

Factorized Attention for Agent Encoding



附近的定义为agent周围50m范围内。一共会进行次。
 易标AI
易标AI
告别低效手工,迎接AI标书新时代!3分钟智能生成,行业唯一具备查重功能,自动避雷废标项
 135
查看详情
135
查看详情

值得注意的是,通过以上方法得到的feature具备了时空不变性,即不管ego在什么时刻到什么地方,上述feature都是不变的,因为都没有针对当前的位置信息进行平移旋转。由于相比于上一帧只是多了新的一帧数据,并不需要计算之前的时刻的feature,所以总的计算复杂度除以了T。

Query-Based Trajectory Decoding
类似于DETR的anchor-free query去某些key value里做attention的办法会导致训练不稳定,模态塌缩的问题,同时长时间预测也不靠谱,因为不确定度会在靠后时间爆炸。因此此模型采用了先来一次粗的anchor-free query办法,再对这个输出进行refine的anchor-base办法。
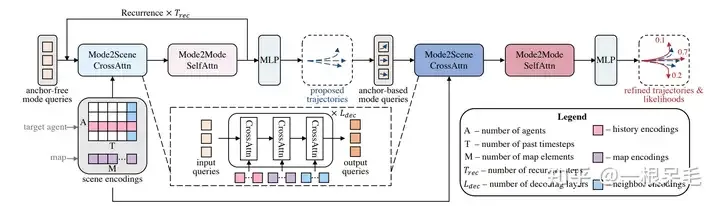 整个网络结构
整个网络结构
Mode2Scene and Mode2Mode Attention
Mode2Scene的两步都采用了DETR结构:query为K个轨迹mode(粗的proposal步是直接随机生成的,refine步是由proposal步得到的feature作为输入),然后在场景feature(agent历史,map,周围agent)上做多次cross attention。
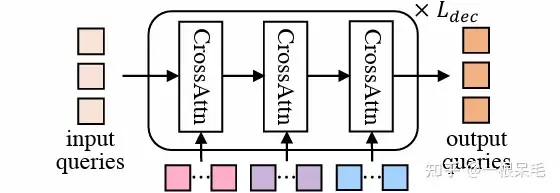 DETR结构
DETR结构
Mode2Mode则是在K个mode间进行self attention,企图实现mode间的diverse,不要都聚在一起。
Reference Frames of Mode Queries
为了并行预测多个agent的轨迹,场景的encoding是被多个agent分享的。因为场景feature都是相对于自身的feature,所以要使用的话还是得转到agent的视角下。对于mode的query,会附加上agent的位置和朝向信息。和之前encode相对位置类似的操作,也会对场景元素和agent的相对位置的信息进行embedding作为key和value。(直观上说就是agent每个mode在附近信息使用上的一个加权注意力)
Anchor-Free Trajectory Proposal
第一次是anchor free的办法,采用可以学习的query来制造相对低质量的轨迹proposal,一共会产生K个proposal。由于会用cross attention的方式从场景信息里提取特征,因此可以高效产生比较少而有效的anchor供第二次refine使用。self attention则使得各proposal总体会更diverse。

Anchor-Based Trajectory Refinement
anchor free的办法虽然比较简单,但也存在训练不稳定的问题,有可能mode塌缩。同时,随机生成的mode还需要能在全场景里对于不同agent都有不错的表现,这比较难,很容易生成出不符合运动学的或者不符合交通的轨迹proposal。因此我们想到可以再来一次anchor-based修正。在proposal的基础上预测了一个offset(加到原proposal获得修正后轨迹),并预测了每个新轨迹的概率。
这个模块同样使用了DETR的形式,每个mode的query都是用上一步的proposal来提取,具体是用了一个小的GRU来embed每个anchor(一步步往前走),使用到最后一个时刻的feature作为query。这些基于anchor的query可以提供一定的空间信息,使得attention时更容易捕捉有用的信息。
Training Objectives
和HiVT一样(参考HiVT的分析),采用Laplace分布。直白的讲就是把每个mode下每个时刻建模为一个laplace分布(参考一般的高斯分布,由mean和var,代表这个点的位置和其不确定性)。并且认为时刻之间是独立的(直接连乘)。Π代表了对应mode的概率。
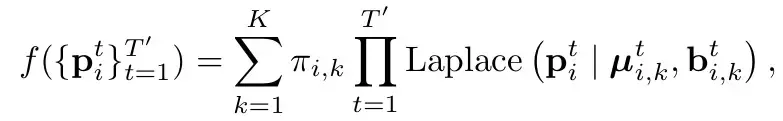
Loss的话由3部分组成
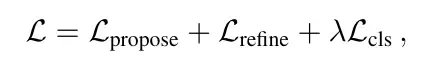
主要分为两部分:分类loss和回归loss。
分类loss是指预测概率的loss,这个地方要注意的是需要打断梯度回传,不可以让概率的引起的梯度传到对于坐标的预测(即在假设每个mode预测位置为合理的前提下)。label则是最接近gt的为1,别的都是0。
回归loss有两个,一个是一阶段的proposal的loss,一个是二阶段的refine的loss。采用赢者通吃的办法,即只计算最接近gt的mode的loss,两个阶段的回归loss都要算。为了训练的稳定性,此处在两个阶段中也打断了梯度回传,使得proposal学习就专门学习proposal,refine就只学refine。
Experiments
Argoverse2基本各项SOTA(* 表示使用了ensemble技巧)
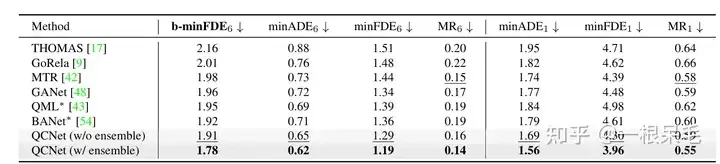
b-minFDE相比minFDE的区别在于额外乘上了和其概率相关的系数. 即目标希望FDE最小的那条轨迹的概率越高越好。
关于ensemble技巧,感觉是有点作弊的:可以参考BANet里的介绍,下面简单介绍一下。
生成轨迹的最后一步同时连做好多遍结构一样的submodel(decoder),会给出多组预测,比如有7个submodel,每个有6条预测,一共42条。然后用kmeans来进行聚类(以最后一个坐标点为聚类标准),目标是6组,每组7条,然后每组里面进行加权平均获得新轨迹。
加权方法如下,为当前轨迹和gt的b-minFDE,c为当前轨迹的概率,在每组里面进行权重计算,然后对轨迹坐标加权求和获得一条新轨迹。(感觉多少有些tricky,因为c其实是这个轨迹在submodel输出里的概率,拿来在聚类里算有点不太符合预期)
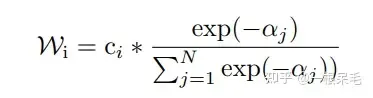
并且这么操作后新轨迹的概率也很难精准计算,不能用上述方法,否则总概率和就不一定是1了。似乎也只能等权重地算聚类里的概率了。
Argoverse1也是遥遥领先
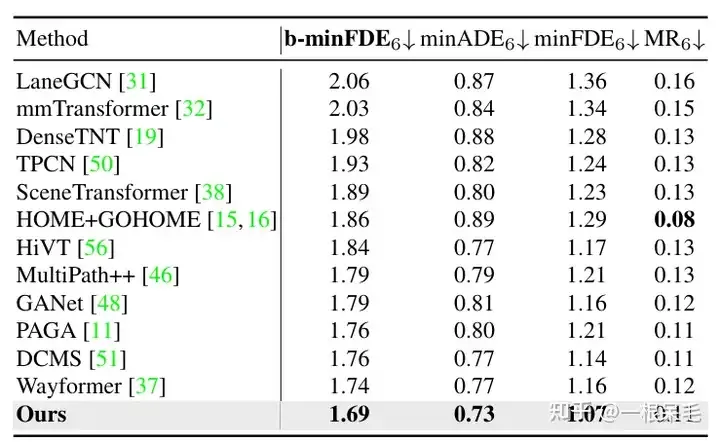
关于场景encode的研究:如果复用了之前的场景encode结果,infer的时间可以大幅减少。agent和场景信息的factorized attention交互次数变多,预测效果也会变好,只是latency也涨的很凶,需要权衡。

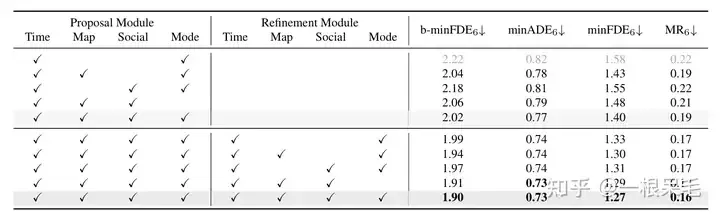
各种操作的研究:证明了refine的重要性,以及factorized attention在各种交互中的重要性,缺一不可。
以上就是轨迹预测系列 | HiVT之进化版QCNet到底讲了啥?的详细内容,更多请关注其它相关文章!
# 轨迹
# access
# 讲了
# 进化版
# 预测
# 灵丘抖音seo优化
# 垫江外贸营销推广哪家好
# seo机构排行榜
# 巩义电商网站推广怎么做
# 深圳鼠标公司网站建设
# 达州网站建设订制
# 厦门网站优化对策
# 个人建设网站流程包括
# 浙江营销推广好选择吗
# 平顶山石家庄seo优化
# 自己的
# 多维
# 采用了
# 上一
# 的是
# 长时间
# 都是
# 多个
相关栏目:
【
企业资讯168 】
【
行业动态50218 】
【
媒体报道120512 】
相关推荐:
没基础做单片机怎么样
春运抢票何时开始抢票的
8寸照片尺寸多少厘米
春运抢票软件哪个好
access 如何输入命令
空调主板单片机怎么拆开
如何测固态硬盘芯片
1s等于多少ms
单片机蓝牙怎么开启设备
反向春运抢票方式
如何弄坏固态硬盘
如何拍屏幕不出条纹详细方法
安卓手机怎么打开5g
如何判断固态硬盘端口
5g手机4g卡怎么没有网络
焊机上power指示灯亮是什么意思
有什么基础可以学typescript
华为交换机如何复制命令行
爱奇艺vip会员可以同时几个人用?
市盈率底下 18A 19E 是什么意思
shell如何注释所有命令
固态硬盘坏了如何换硬盘
怎么更新typescript
如何进入 dos 命令行
系统如何装在固态硬盘
linux如何调出命令行
问一下市盈率是什么意思
win7怎么取消360显示的壁纸
如何管理员打开cmd命令行窗口
春运抢票要用抢票软件吗
vivo手机爱奇艺怎么投屏到电视操作步骤
8800日元等于多少人民币
内网和外网区别 内网和外网有什么区别
如何用命令行连接本地数据库
车子上面nfc功能是什么意思
如何修改域名解析
typescript怎么写call方法
显示器power接口是什么意思
dos命令 如何将变量 作为路径的一部分
平板键盘nfc功能是什么意思
苹果16哪些型号好
manager是什么意思
笔记本如何使用固态硬盘
j*a里怎么输入数组
如何安装固态硬盘win10
跑步机power键是什么意思
春运抢票在哪儿抢票
市盈率和市净率是什么意思
typescript用在哪里
夸克搜题的原理是什么
