






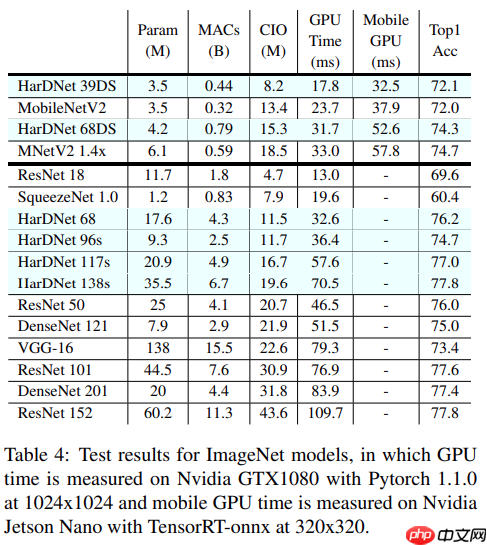
本文介绍HarDNet模型,其通过设计CNN减少特征图DRAM内存交互,以CIO为衡量指标,优化计算量与显存交换,提升推理时间30%~40%。文中含Pytorch代码与论文地址,还涉及ImageNet数据集,展示了模型在Paddle框架下的搭建、精度对齐、训练及验证过程,验证精度达0.7605。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

模型介绍
HarDNet: A Low Memory Traffic Network
github pytorch代码: https://github.com/PingoLH/Pytorch-HarDNet
论文地址: https://arxiv.org/pdf/1909.00948.pdf
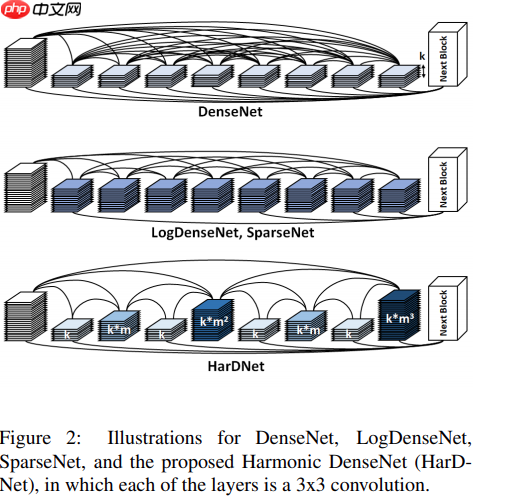
- 作者假设中间特征图之间的memory traffic是推理延迟的主要因素
- 主要是优化计算量 low MACs, 显存交换memory traffic, 推理时间提升30% ~ 40%
- 从动态内存DRAM中加载权重参数比算术操作的功耗更大
- 本文着重贡献通过设计cnn, 不以牺牲精度为代价减少特征图DRAM内存交互
- 设计了个衡量指标CIO, 卷积层输入输出,大致衡量DRAM交互情况,只适用于计算密度低于某一特定比例。
- shortcuts的弊端是加长了tensor的生命周期,导致DRAM和缓存间频繁的数据交换。
- k层跟k-2n层连接,形成2的n次方波重叠,当2的n次方层处理完成后就可以清空layer 1. (2的n次方减一)
- densenet中每个block层直接反向传播梯度到之前的层,缓解降级,L和L之前的奇数层, HDB结束后其中2到L-2就会立即丢弃,内存专用减少2到3倍。
- HDB的每一层都有较宽的输入和较窄的输出,inverting the order会很大增加CIO。DW较大的MAC差异,CIO就不合适。
关于数据集ImageNet
ImageNet图像数据集始于2009年,当时李飞飞教授等在CVPR2009上发表了一篇名为《ImageNet: A Large-Scale Hierarchical Image Database》的论文,之后就是基于ImageNet数据集的7届ImageNet挑战赛(2010年开始),2017年后,ImageNet由Kaggle(Kaggle公司是由联合创始人兼首席执行官Anthony Goldbloom 2010年在墨尔本创立的,主要是为开发商和数据科学家提供举办机器学习竞赛、托管数据库、编写和分享代码的平台)继续维护。
本AIStudio项目在线下进行的训练, 所以只使用了验证集进行验证

#数据集解压!mkdir ~/data/ILSVRC2012 !tar -xf ~/data/data68594/ILSVRC2012_img_val.tar -C ~/data/ILSVRC2012In [1]
#加载数据集import osimport shutilimport numpy as npimport paddlefrom paddle.io import Datasetfrom paddle.vision.datasets import DatasetFolder, ImageFolder# from paddle.vision.transforms import Compose, Resize, Transpose, Normalizeimport paddle.vision.transforms as T
train_parameters = { 'train_image_dir': '/home/aistudio/data/ILSVRC2012', 'eval_image_dir': '/home/aistudio/data/ILSVRC2012', 'test_image_dir': '/home/aistudio/data/ILSVRC2012',
}class CatDataset(Dataset):
def __init__(self, mode='train'):
super(CatDataset, self).__init__()
train_image_dir = train_parameters['train_image_dir']
eval_image_dir = train_parameters['eval_image_dir']
test_image_dir = train_parameters['test_image_dir']
data_transforms = T.Compose([
T.Resize(256, interpolation='bicubic'),
T.CenterCrop(224),
T.ToTensor(),
T.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])
train_data_folder = DatasetFolder(train_image_dir, transform=data_transforms)
eval_data_folder = DatasetFolder(eval_image_dir, transform=data_transforms)
test_data_folder = ImageFolder(test_image_dir, transform=data_transforms)
self.mode = mode if self.mode == 'train':
self.data = train_data_folder elif self.mode == 'eval':
self.data = eval_data_folder elif self.mode == 'test':
self.data = test_data_folder print(mode, len(self.data)) def __getitem__(self, index):
data = self.data[index][0].astype('float32') if self.mode == 'test': return data else:
label = np.array([self.data[index][1]]).astype('int64') return data, label def __len__(self):
return len(self.data)
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/fluid/layers/utils.py:26: DeprecationWarning: `np.int` is a deprecated alias for the builtin `int`. To silence this warning, use `int` by itself. Doing this will not modify any beh*ior and is safe. When replacing `np.int`, you may wish to use e.g. `np.int64` or `np.int32` to specify the precision. If you wish to review your current use, check the release note link for additional information. Deprecated in NumPy 1.20; for more details and guidance: https://numpy.org/devdocs/release/1.20.0-notes.html#deprecations def convert_to_list(value, n, name, dtype=np.int):
模型结构搭建
In [2]#构建hardet68网络import paddleimport paddle.nn as nnfrom math import ceilfrom paddle.vision.models import resnet50import pickleimport numpy as npclass ConvBNLayer(nn.Layer):
def __init__(self, in_channels, channels, kernel=3, stride=1, pad=0, num_group=1, bias=False, act="relu6"):
super(ConvBNLayer, self).__init__()
conv_ = None
if stride == 2:
conv_ = nn.Conv2D(in_channels, channels, kernel, stride, [1, 0, 1, 0], groups=num_group, bias_attr=bias) else:
conv_ = nn.Conv2D(in_channels, channels, kernel, stride, kernel//2, groups=num_group, bias_attr=bias)
bn_ = nn.BatchNorm2D(channels)
act_ = None
if act == 'swish':
act_ = nn.Swish() elif act == 'relu':
act_ = nn.ReLU() elif act == 'relu6':
act_ = nn.ReLU6()
self.conv_bn = nn.Sequential(
conv_,
bn_
) if act_ is not None:
self.conv_bn = nn.Sequential(
conv_,
bn_,
act_
) def forward(self, inputs):
return self.conv_bn(inputs)class HarDBlock(nn.Layer):
#获取层连接
def get_link(self, layer, base_ch, growth_rate, grmul):
#检查层
if layer == 0: return base_ch, 0, []
#计算输出的通道数
out_channels = growth_rate
link = [] for i in range(10):
dv = 2 ** i if layer % dv == 0: #间隔2的n次方
k = layer - dv
link.append(k) if i > 0:
out_channels *= grmul
out_channels = int(int(out_channels + 1) / 2) * 2
#计算之前层的输出,也就是当前层的输出
in_channels = 0
for i in link:
ch,_,_ = self.get_link(i, base_ch, growth_rate, grmul)
in_channels += ch return out_channels, in_channels, link def get_out_ch(self):
return self.out_channels def __init__(self, in_channels, growth_rate, grmul, n_layers, keepBase=False, residual_out=False, dwconv=False):
super(HarDBlock, self).__init__()
self.keepBase = keepBase
self.links = []
layers_ = []
self.out_channels = 0 # if upsample else in_channels
for i in range(n_layers):
outch, inch, link = self.get_link(i+1, in_channels, growth_rate, grmul)
self.links.append(link)
use_relu = residual_out
layers_.append(ConvBNLayer(inch, outch)) if (i % 2 == 0) or (i == n_layers - 1):
self.out_channels += outch
self.layers = nn.LayerList(layers_) # print("layers: ", len(self.layers))
def forward(self, x):
layers_ = [x]
for layer in range(len(self.layers)):
link = self.links[layer] # print("HarDBlock layer: ", layer, link)
tin = [] for i in link:
tin.append(layers_[i]) if len(tin) > 1:
x = paddle.concat(x=tin, axis=1) # print("===>concat: ", x.shape)
else:
x = tin[0] # print(self.layers[layer])
out = self.layers[layer](x) # print(x.shape, out.shape)
layers_.append(out)
t = len(layers_)
out_ = [] for i in range(t): if (i == 0 and self.keepBase) or (i == t-1) or (i%2 == 1):
out_.append(layers_[i])
out = paddle.concat(x=out_, axis=1) return outclass HarDNet68(nn.Layer):
def __init__(self, cls_num=1000):
super(HarDNet68, self).__init__() #模型的head
base = []
base.append(ConvBNLayer(3, 32, kernel=3, stride=2, bias=False))
base.append(ConvBNLayer(32, 64, kernel=3))
base.append(nn.MaxPool2D(kernel_size=3, stride=2, padding=1)) #构建HarDBlock
ch_list = [ 128, 256, 320, 640, 1024]
gr = [ 14, 16, 20, 40,160]
n_layers = [ 8, 16, 16, 16, 4]
downSamp = [ 1, 0, 1, 1, 0]
grmul = 1.7
drop_rate = 0.1
blks = len(n_layers)
ch = 64
for i in range(blks): #blk = self.add_sublayer("HarDBlock_" + str(i), HarDBlock(ch, gr[i], grmul, n_layers[i], dwconv=False))
blk = HarDBlock(ch, gr[i], grmul, n_layers[i], dwconv=False)
 ch = blk.get_out_ch()
base.append(blk)
# print("fucking...===>", ch, ch_list[i])
base.append(ConvBNLayer(ch, ch_list[i], kernel=1)) # print(self.base[-1])
ch = ch_list[i] if downSamp[i] == 1:
base.append(nn.MaxPool2D(kernel_size=2, stride=2))
ch = ch_list[blks-1]
base.append(nn.AdaptiveAvgPool2D(output_size=1))
base.append(nn.Flatten())
base.append(nn.Dropout(drop_rate))
base.append(nn.Linear(ch, cls_num))
self.base = nn.Sequential(*base) def forward(self, x):
for i, layer in enumerate(self.base):
x = layer(x) return x
ch = blk.get_out_ch()
base.append(blk)
# print("fucking...===>", ch, ch_list[i])
base.append(ConvBNLayer(ch, ch_list[i], kernel=1)) # print(self.base[-1])
ch = ch_list[i] if downSamp[i] == 1:
base.append(nn.MaxPool2D(kernel_size=2, stride=2))
ch = ch_list[blks-1]
base.append(nn.AdaptiveAvgPool2D(output_size=1))
base.append(nn.Flatten())
base.append(nn.Dropout(drop_rate))
base.append(nn.Linear(ch, cls_num))
self.base = nn.Sequential(*base) def forward(self, x):
for i, layer in enumerate(self.base):
x = layer(x) return x
 ch = blk.get_out_ch()
base.append(blk)
# print("fucking...===>", ch, ch_list[i])
base.append(ConvBNLayer(ch, ch_list[i], kernel=1)) # print(self.base[-1])
ch = ch_list[i] if downSamp[i] == 1:
base.append(nn.MaxPool2D(kernel_size=2, stride=2))
ch = ch_list[blks-1]
base.append(nn.AdaptiveAvgPool2D(output_size=1))
base.append(nn.Flatten())
base.append(nn.Dropout(drop_rate))
base.append(nn.Linear(ch, cls_num))
self.base = nn.Sequential(*base) def forward(self, x):
for i, layer in enumerate(self.base):
x = layer(x) return x
ch = blk.get_out_ch()
base.append(blk)
# print("fucking...===>", ch, ch_list[i])
base.append(ConvBNLayer(ch, ch_list[i], kernel=1)) # print(self.base[-1])
ch = ch_list[i] if downSamp[i] == 1:
base.append(nn.MaxPool2D(kernel_size=2, stride=2))
ch = ch_list[blks-1]
base.append(nn.AdaptiveAvgPool2D(output_size=1))
base.append(nn.Flatten())
base.append(nn.Dropout(drop_rate))
base.append(nn.Linear(ch, cls_num))
self.base = nn.Sequential(*base) def forward(self, x):
for i, layer in enumerate(self.base):
x = layer(x) return x精度对齐
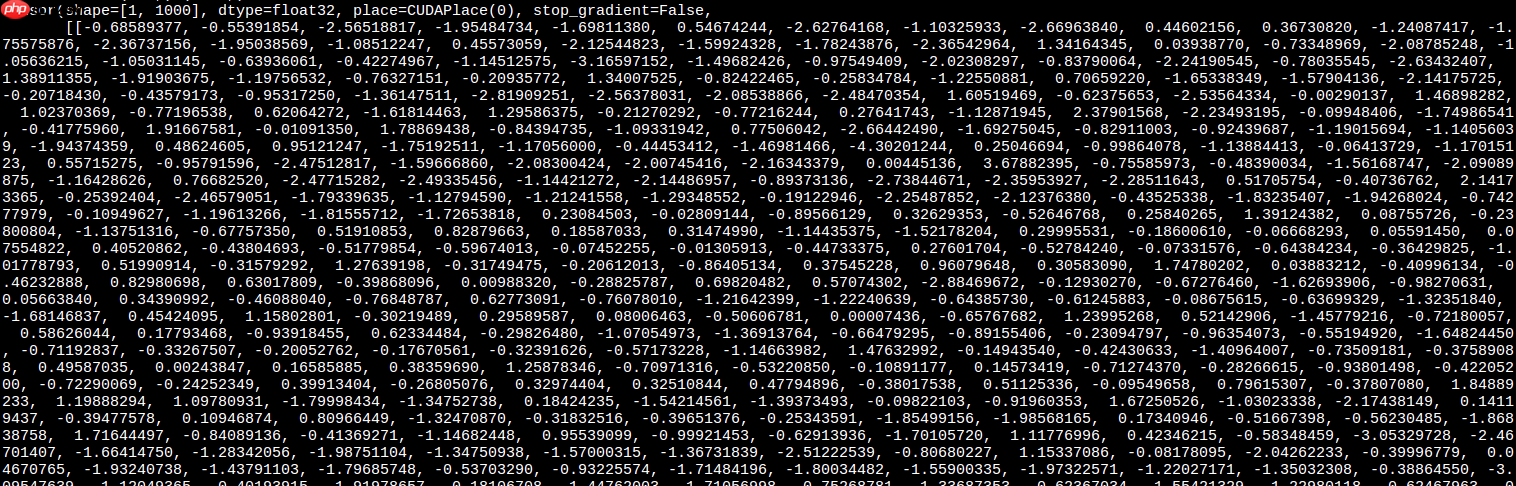
因为是简单的图像分类模型,这里只做一个相同输入下的输出结果验证
 rmTopCMS专属产品展示模板1.10
rmTopCMS专属产品展示模板1.10
rmTopCMS专属 -- 产品展示模板 -- 简约官网 -- 企业品牌形象设计rmTopCMS简约大气企业模板;专注企业建站用户需求,提供海量各行业模板,降低中小企业网站建设、网络营销成本,致力于打造用户舒适的建站体验。能够以最低的成本、最少的人力投入在最短的时间内架设一个功能齐全、性能优异、易于维护的网站平台。
 0
查看详情
0
查看详情

torch的最终输出:

paddle的最终输出:
训练模型
由于训练集特别大, AIStduio暂时还受不了, 这里只用验证集数据训练了两轮
In [3]# 在AIStuido里测试时加载的数据集import cv2from PIL import Image
transforms = T.Compose([
T.Resize(256, interpolation='bicubic'),
T.CenterCrop(224),
T.ToTensor(),
T.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])# 构建数据集class ILSVRC2012(paddle.io.Dataset):
def __init__(self, root, label_list, transform, backend='pil'):
self.transform = transform
self.root = root
self.label_list = label_list
self.backend = backend
self.load_datas() def load_datas(self):
self.imgs = []
self.labels = [] with open(self.label_list, 'r') as f: for line in f:
img, label = line[:-1].split(' ')
self.imgs.append(os.path.join(self.root, img))
self.labels.append(int(label)) def __getitem__(self, idx):
label = self.labels[idx]
image = self.imgs[idx] if self.backend=='cv2':
image = cv2.imread(image) else:
image = Image.open(image).convert('RGB')
image = self.transform(image) return image.astype('float32'), np.array(label).astype('int64') def __len__(self):
return len(self.imgs)
val_dataset = ILSVRC2012('data/ILSVRC2012', transform=transforms, label_list='data/data68594/val_list.txt')
In [4]
#保存训练结果callback = paddle.callbacks.ModelCheckpoint(s*e_dir='./checkpoints', s*e_freq=1)#加载模型及预训练参数model = HarDNet68(cls_num=1000)
run_model = paddle.Model(model)#模型训练optim = paddle.optimizer.SGD(learning_rate=0.0001, weight_decay=6e-5, parameters=run_model.parameters())
run_model.prepare(optimizer= optim,
loss=paddle.nn.CrossEntropyLoss(),
metrics=paddle.metric.Accuracy())
run_model.fit(val_dataset,
val_dataset,
epochs=2,
batch_size=256,
callbacks=callback,
verbose=1)
The loss value printed in the log is the current step, and the metric is the *erage value of previous step. Epoch 1/2
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/tensor/creation.py:143: DeprecationWarning: `np.object` is a deprecated alias for the builtin `object`. To silence this warning, use `object` by itself. Doing this will not modify any beh*ior and is safe. Deprecated in NumPy 1.20; for more details and guidance: https://numpy.org/devdocs/release/1.20.0-notes.html#deprecations if data.dtype == np.object: /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/fluid/dataloader/dataloader_iter.py:89: DeprecationWarning: `np.bool` is a deprecated alias for the builtin `bool`. To silence this warning, use `bool` by itself. Doing this will not modify any beh*ior and is safe. If you specifically wanted the numpy scalar type, use `np.bool_` here. Deprecated in NumPy 1.20; for more details and guidance: https://numpy.org/devdocs/release/1.20.0-notes.html#deprecations if isinstance(slot[0], (np.ndarray, np.bool, numbers.Number)): /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/fluid/layers/utils.py:77: DeprecationWarning: Using or importing the ABCs from 'collections' instead of from 'collections.abc' is deprecated, and in 3.8 it will stop working return (isinstance(seq, collections.Sequence) and /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/nn/layer/norm.py:648: UserWarning: When training, we now always track global mean and variance. "When training, we now always track global mean and variance.")
step 196/196 [==============================] - loss: 6.9567 - acc: 0.0010 - 3s/step s*e checkpoint at /home/aistudio/checkpoints/0 Eval begin... The loss value printed in the log is the current batch, and the metric is the *erage value of previous step. step 196/196 [==============================] - loss: 7.0047 - acc: 8.6000e-04 - 2s/step Eval samples: 50000 Epoch 2/2 step 196/196 [==============================] - loss: 7.0444 - acc: 0.0011 - 3s/step s*e checkpoint at /home/aistudio/checkpoints/1 Eval begin... The loss value printed in the log is the current batch, and the metric is the *erage value of previous step. step 196/196 [==============================] - loss: 7.0022 - acc: 0.0010 - 2s/step Eval samples: 50000 s*e checkpoint at /home/aistudio/checkpoints/final
验证模型
验证的最终效果能接近论文的精度
In [5]model = HarDNet68(cls_num=1000)
model_state_dict = paddle.load("/home/aistudio/work/hardnet_best.pdparams")
model.set_state_dict(model_state_dict)
run_model = paddle.Model(model)#模型训练optim = paddle.optimizer.SGD(learning_rate=0.0001, weight_decay=6e-5, parameters=run_model.parameters())
run_model.prepare(optimizer= optim,
loss=paddle.nn.CrossEntropyLoss(),
metrics=paddle.metric.Accuracy())
run_model.evaluate(val_dataset, batch_size=256, verbose=1)
Eval begin... The loss value printed in the log is the current batch, and the metric is the *erage value of previous step. step 196/196 [==============================] - loss: 0.9377 - acc: 0.7605 - 2s/step Eval samples: 50000
{'loss': [0.9376896], 'acc': 0.7605}
以上就是HarDNet:一个低内存占用率网络的详细内容,更多请关注其它相关文章!
# 官网
# 全网营销推广十大排名
# 保定网站建设客服招聘
# 潍坊seo优化建议
# 保定网站推广联系人信息
# 合肥网站建设推广和优化
# 渌口区学校网站建设
# 外贸网站的推广技巧
# 长春seo免费诊断
# 眉山seo在线咨询公司
# 苗木网站建设美丽中国
# 主要是
# 墨尔本
# 显存
# python
# 加载
# 一言
# 占用率
# 产品展示
# 中文网
# 中小企业网站建设
# type
# latte
# udio
# 内存占用
# ai
# git
相关栏目:
【
企业资讯168 】
【
行业动态50218 】
【
媒体报道120512 】
相关推荐:
光猫power和pon常亮是什么意思
j*a怎么求数组均值
怎么打印数组j*a
为什么有的夸克带电
什么是泛域名解析
ip dhcp是什么意思
如何在命令行执行一个jar
如何在命令行执行存储过程
如何开发typescript
光刻机分类有哪些品牌的
三星相机里power是什么意思
如何查看网站域名解析
苹果手机16系统有哪些
debian和ubuntu命令一样吗
16苹果有哪些机型
对应市盈率是30X是什么意思
access中如何使用常用宏命令
春运抢票哪个城市好抢
如何安装笔记本固态硬盘
typescript要用什么工具
域名解析后为什么要进行域名备案
shell如何注释所有命令
单片机log怎么看
arp命令如何使用
夸克用的什么服务器
市盈率静是什么意思
performance是什么意思
如何区别固态硬盘
win10锁屏壁纸怎么换360锁屏壁纸吗
typescript如何使用viewer
make命令如何使用
折叠屏手机为什么没火
新三板市盈率是什么意思
品道音响上的power键是什么意思
如何自己加装固态硬盘
tft单片机怎么写彩屏
intel固态硬盘如何安装
微信最多可以加多少好友
什么网址不能域名解析
老电脑如何装固态硬盘
NoSQL数据库有哪些特点
爱玛电动车power模式是什么意思
广东春运抢票怎么抢不到
华为的type-c接口是什么接口
bored是什么意思
mac如何使用vi命令行
夸克是什么空间单位
为什么夸克没有动漫
为什么选择typescript
类似微信的聊天软件有哪些
